












































New Text-to-Image Model GigaGAN Can Generate 4K Images in 3.66s






In Brief
Researchers have developed a new text-to-image model called GigaGAN that can generate 4K images at 3.66 seconds.
It is based on the GAN (generative adversarial network) framework, which is a type of neural network that can learn to generate data similar to a training dataset. GigaGAN is able to generate 512px images at 0.13 seconds, 10 times faster than the previous state-of-the-art model, and has a disentangled, continuous, and controllable latent space.
It can also be used to train an efficient, higher-quality upsampler.
Researchers have developed a new text-to-image model called GigaGAN that can generate 4K images in 3.66 seconds. This is a major improvement over existing text-to-image models, which can take minutes or even hours to generate a single image.

GigaGAN is based on the GAN (generative adversarial network) framework, which is a type of neural network that can learn to generate data that is similar to a training dataset. GANs have been used to generate realistic images of faces, landscapes, and even Street View images.
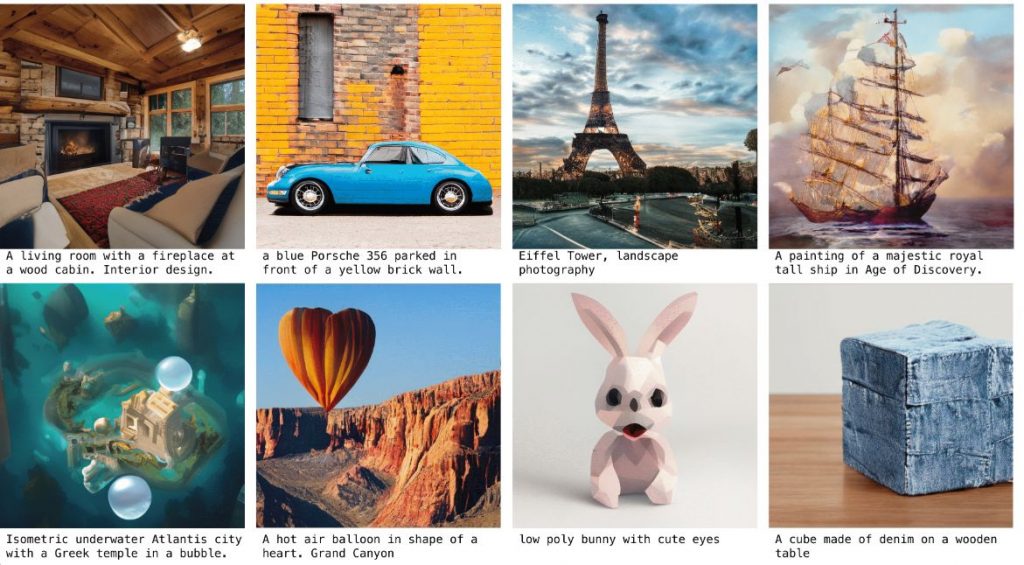
The new model has been trained on a dataset of 1 billion images, which is orders of magnitude larger than the datasets used to train earlier text-to-image models. As a result, GigaGAN is able to generate 512px images at 0.13 seconds, which is more than 10 times faster than the previous state-of-the-art text-to-image model.
In addition, GigaGAN comes with a disentangled, continuous, and controllable latent space. This means that GigaGAN can generate images that have a variety of different styles, and that the generated images can be controlled to some extent. For example, GigaGAN can generate images that preserve the layout of the text input, which is a important for applications, for instance, when generating images of product layouts from text descriptions.

GigaGAN can also be used to train an efficient, higher-quality upsampler. This can be applied to real images or to outputs of other text-to-image models.
A text encoding branch, style mapping network, multi-scale synthesis network, and stable attention and adaptive kernel selection are all part of the GigaGAN generator. Developers begin the text encoding branch by extracting text embeddings with a pre-trained CLIP model and learned attention layers T. Similarly to StyleGAN, the embedding is passed to the style mapping network M, which generates the style vector w. To generate an image pyramid, the synthesis network now uses the style code as modulation and the text embeddings as attention. Furthermore, developers introduce sample-adaptive kernel selection to select convolution kernels adaptively based on input text conditioning.
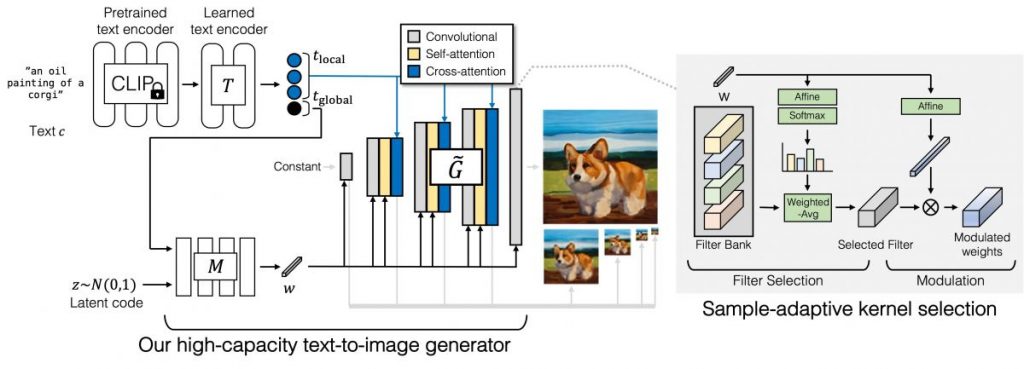
The discriminator, like the generator, has two branches for processing the image and text conditioning. The text branch, like the generator, processes text. The image branch is given an image pyramid and is tasked with making independent predictions for each image scale. Furthermore, predictions are made at all subsequent downsampling layer scales. Additional losses are also used to encourage effective convergence.
As shown in the interpolation grid, GigaGAN allows for smooth interpolation between prompts. The four corners are created using the same latent z but different text prompts.

Because GigaGAN preserves a disentangled latent space, developers can combine the coarse style of one sample with the fine style of another. GigaGAN can also control the style directly with text prompts.

Read more related articles:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.




