












































AI Dementia: The Challenges of Model-Generated Content and its Impact on AI Systems







In Brief
Researchers have uncovered the phenomenon of model dementia, which refers to the irreversible defects that occur in models when the tails of the original content distribution disappear.
To preserve the benefits of training models on internet data, solutions must be found to mitigate the potential loss of original content distribution.
The rapid advancements in AI technology have brought forth incredible achievements in natural language processing and image generation. Large language models (LLMs) like GPT-2, GPT-3 (.5), and GPT-4 have demonstrated remarkable performance across various language tasks, while models such as ChatGPT have introduced these language capabilities to the general public. However, as LLMs become more prevalent, and contribute significantly to the language found online, researchers have uncovered a concerning issue known as “model dementia.”

| Recommended: OpenAI: AI Could Potentially Do a Lot of Harm to People, But Trying to Stop Progress is Not an Option |
In a recent article, researchers shed light on the phenomenon of model dementia, which refers to the irreversible defects that occur in models when the tails of the original content distribution disappear. The study indicates that using model-generated content during training can lead to this cognitive decline in the resulting models. This effect has been observed in variational autoencoders (VAEs), Gaussian mixture models (GMMs), and LLMs. The findings emphasize the need to address this issue to preserve the benefits of training models on large-scale data obtained from the internet.
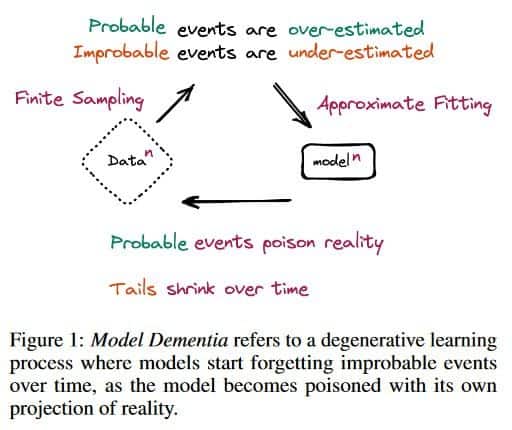
The researchers provide a theoretical understanding of model dementia and demonstrate its prevalence across various generative models. They argue this phenomenon must be taken seriously to ensure the continued effectiveness of training models on extensive web data. As LLMs increasingly contribute to the language and content available online, the value of data collected from genuine human interactions with systems becomes even more critical.
The introduction of stable diffusion, a technique that revolutionized image creation from descriptive text, further exemplifies the impact of LLMs in generating content. However, the study suggests that using model-generated content can cause the loss of tail-end content distribution, potentially eroding the diversity and richness of the original data.
While large-scale data scraped from the web provides valuable insights into human interactions with systems, the presence of content generated by LLMs introduces new challenges. The researchers emphasize the need to address model dementia and find solutions that preserve the benefits of training models on internet data while mitigating the potential loss of original content distribution.
As the field of AI continues to develop, it is crucial for researchers, developers, and policymakers to be aware of the limitations and challenges associated with training models on model-generated content. By understanding and addressing issues like model dementia, we can ensure the responsible and effective use of AI technology in the future.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.




