












































GLIGEN: new frozen text-to-image generation model with bounding box







In Brief
GLIGEN, or Grounded-Language-to-Image Generation, is a novel technique that builds on and extends the capability of current pre-trained diffusion models.
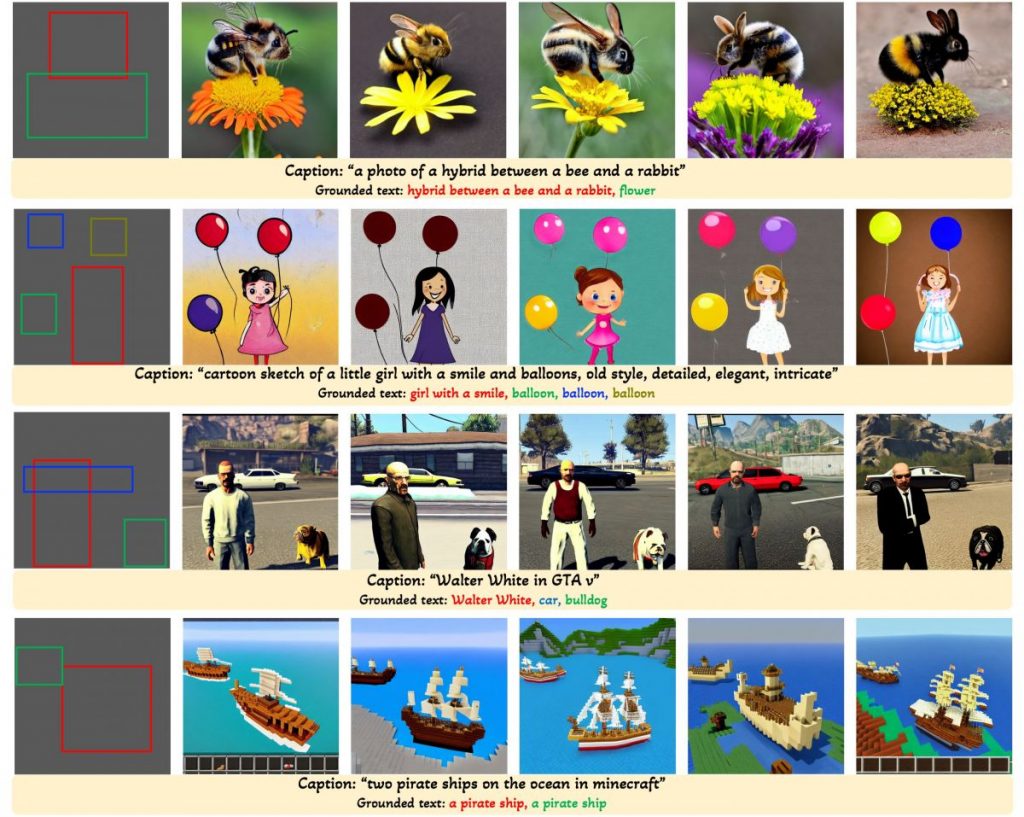
With caption and bounding box condition inputs, GLIGEN model generates open-world grounded text2img.
GLIGEN can generate a variety of objects in specific places and styles by leveraging knowledge from a pretrained text2img model.
GLIGEN may also ground human keypoints while generating text-to-images.
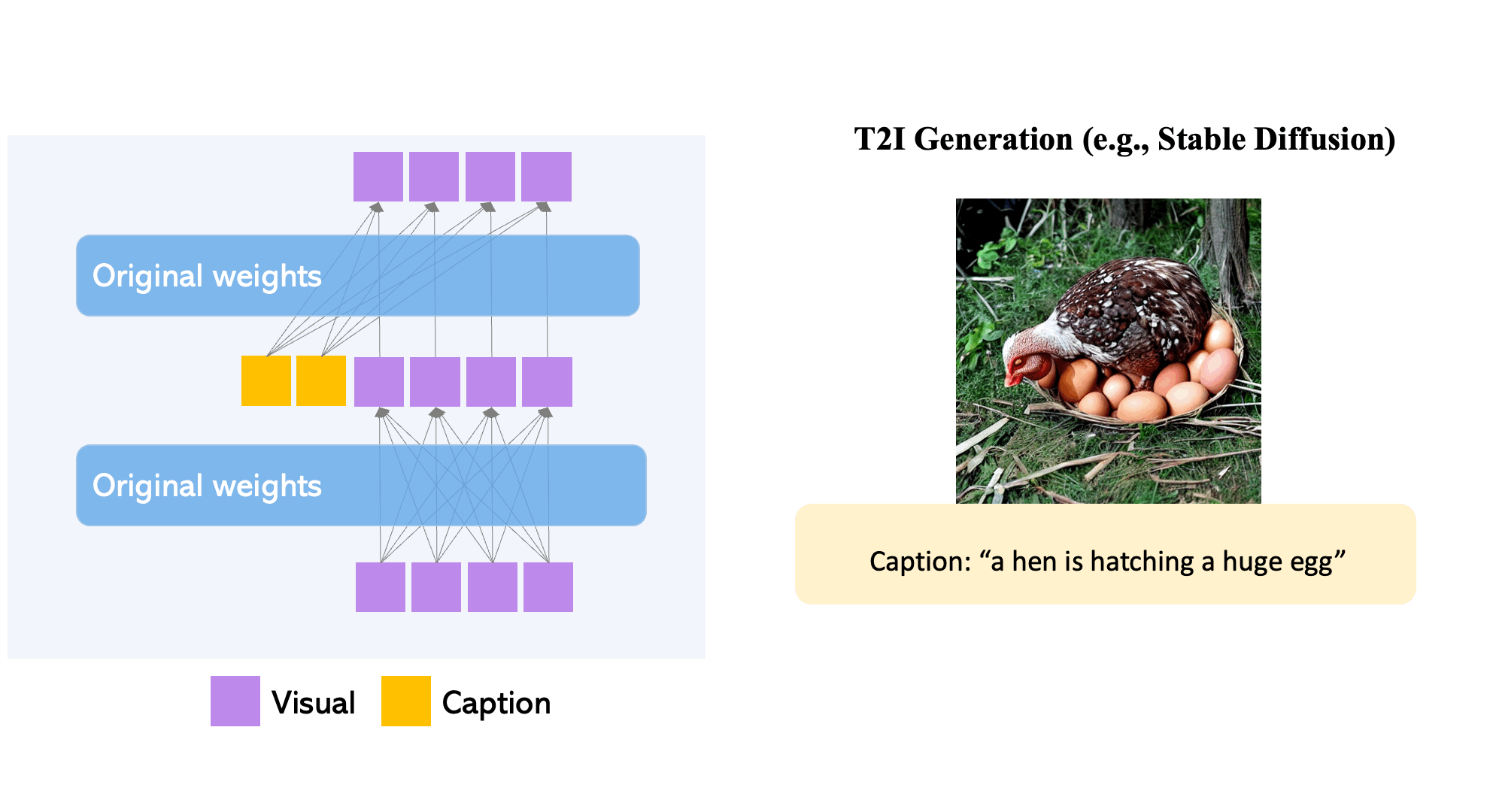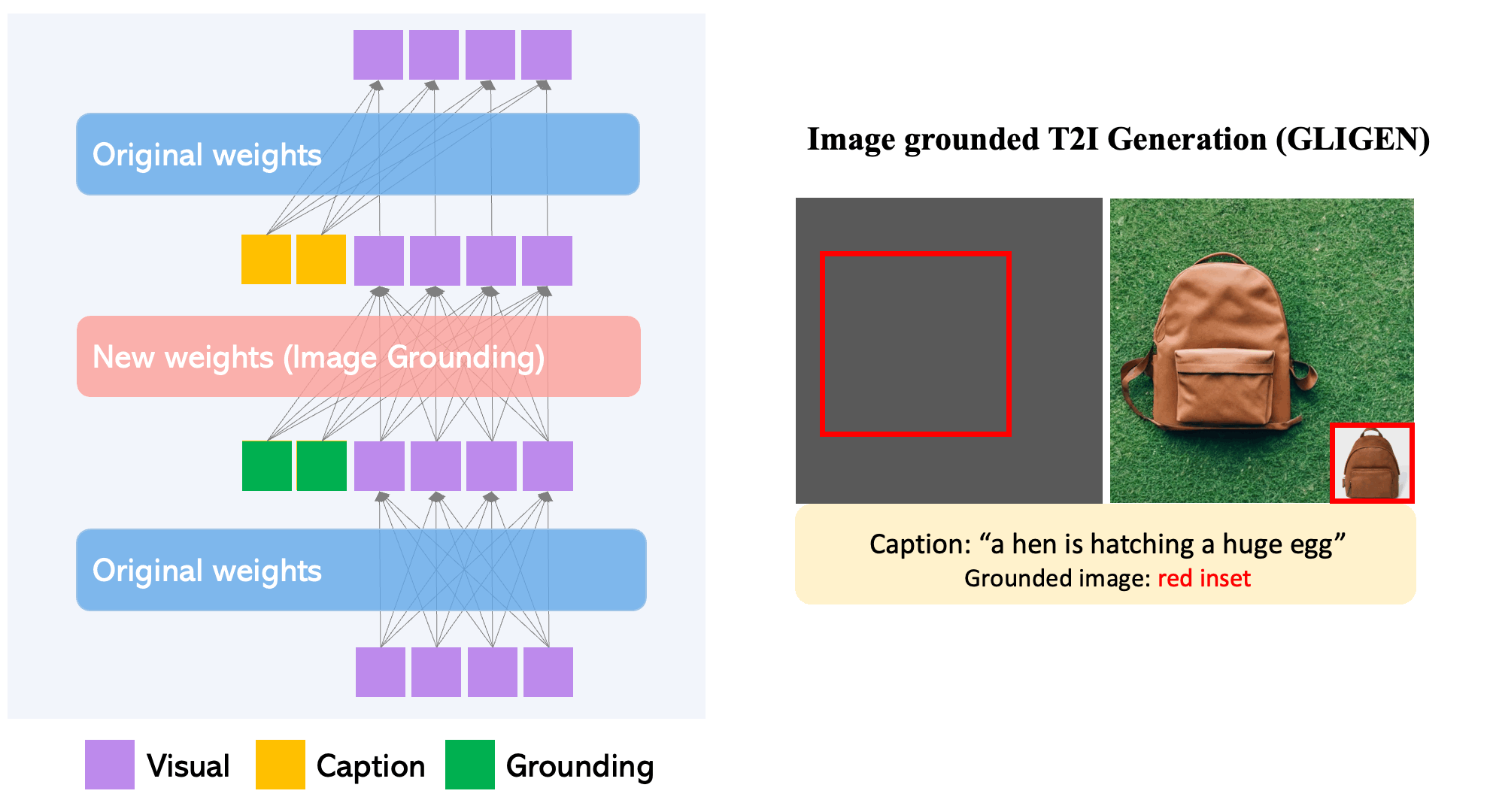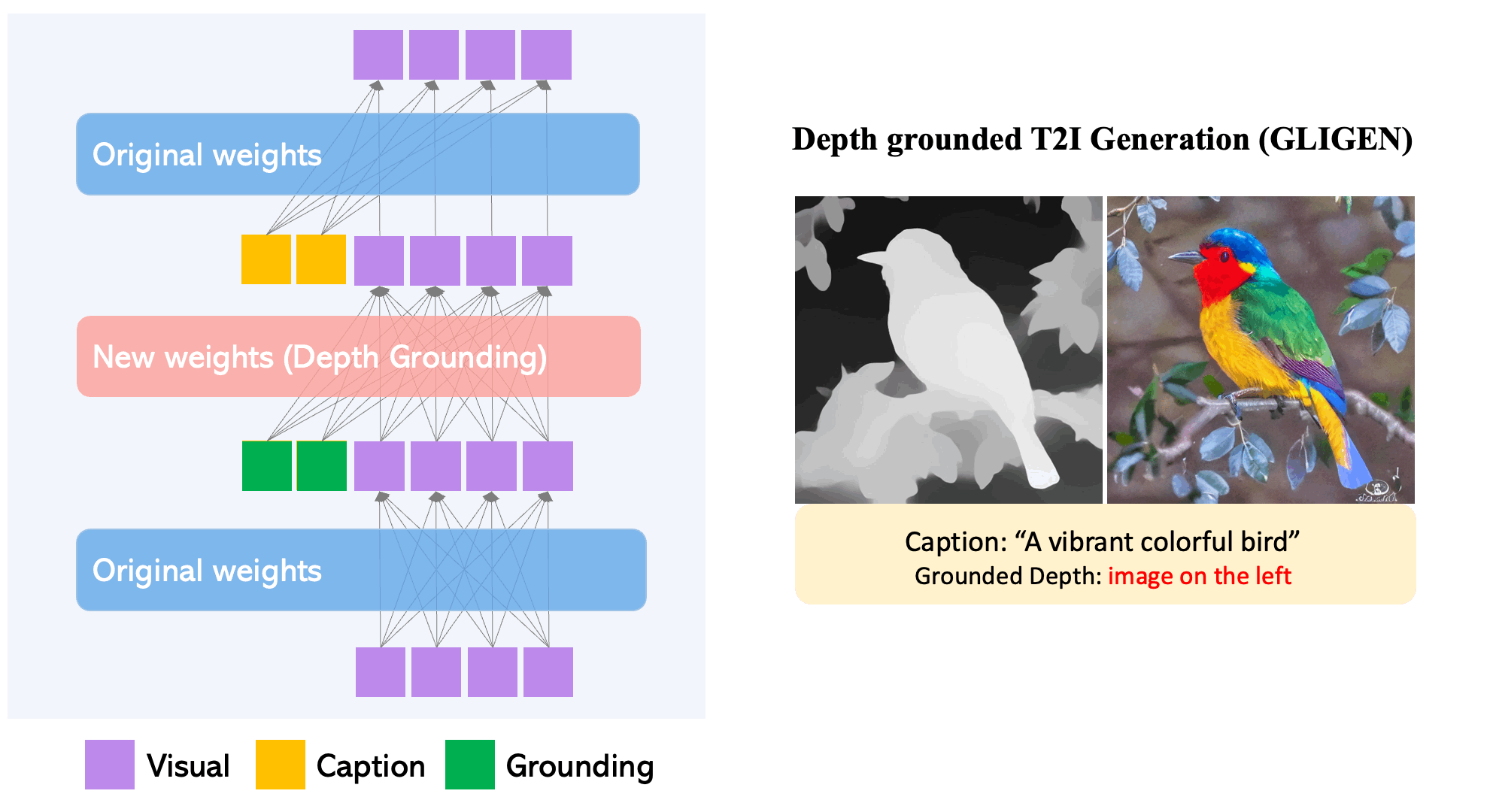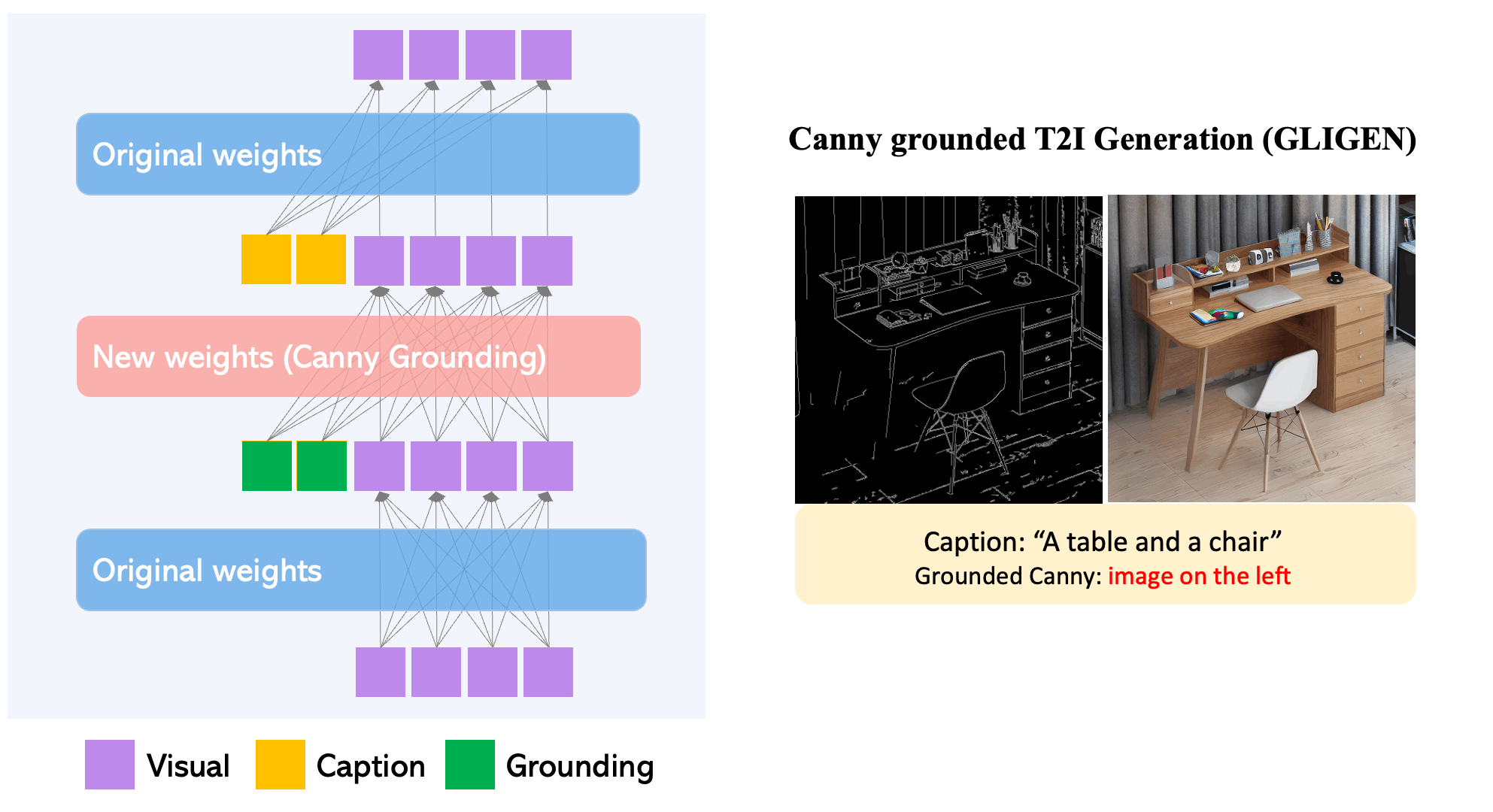
Large-scale text-to-image diffusion models have come a long way. However, the current practice is to rely solely on text input, which can limit controllability. GLIGEN, or Grounded-Language-to-Image Generation, is a novel technique that builds on and extends the capability of current pre-trained text-to-image diffusion models by allowing them to be conditioned on grounding inputs.

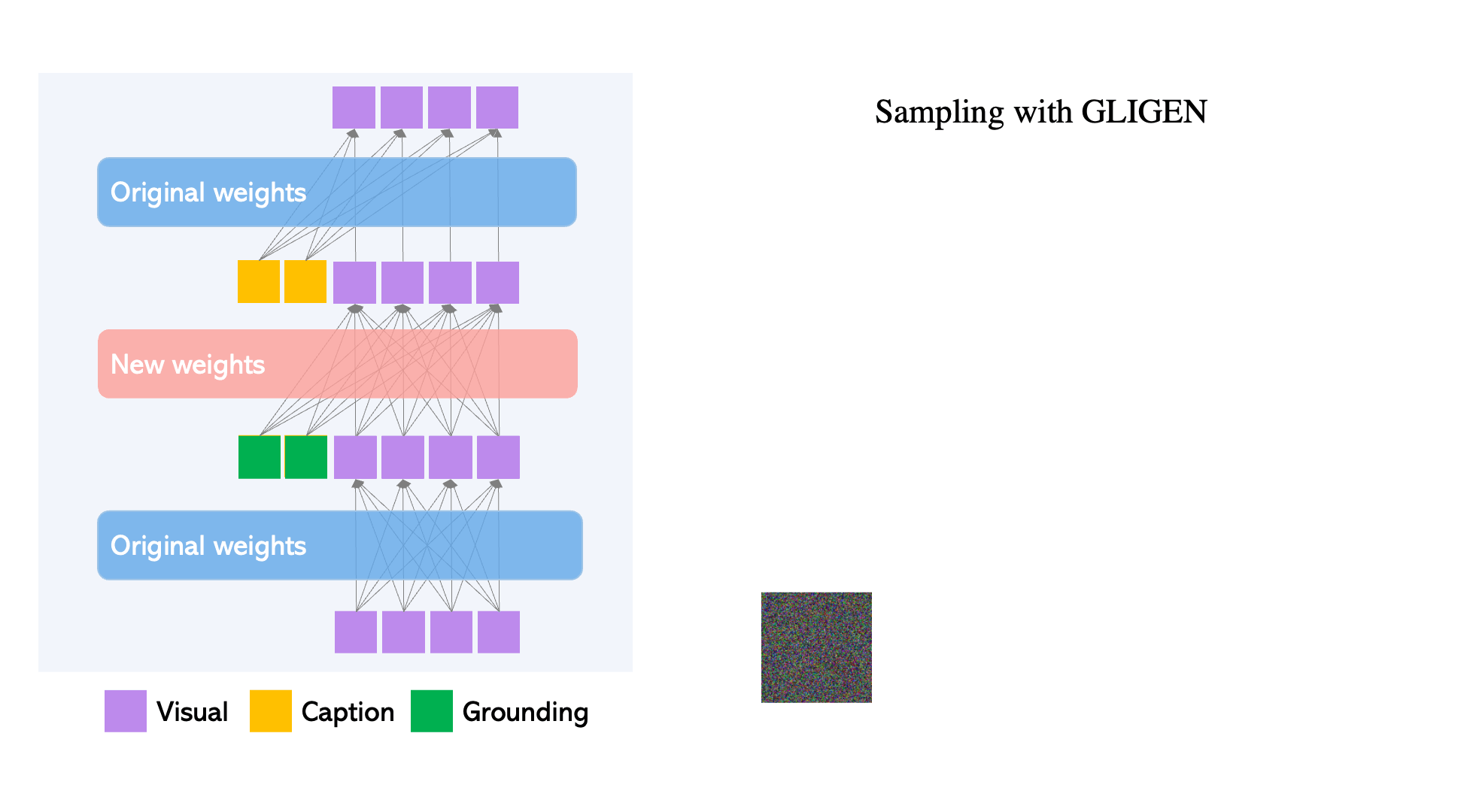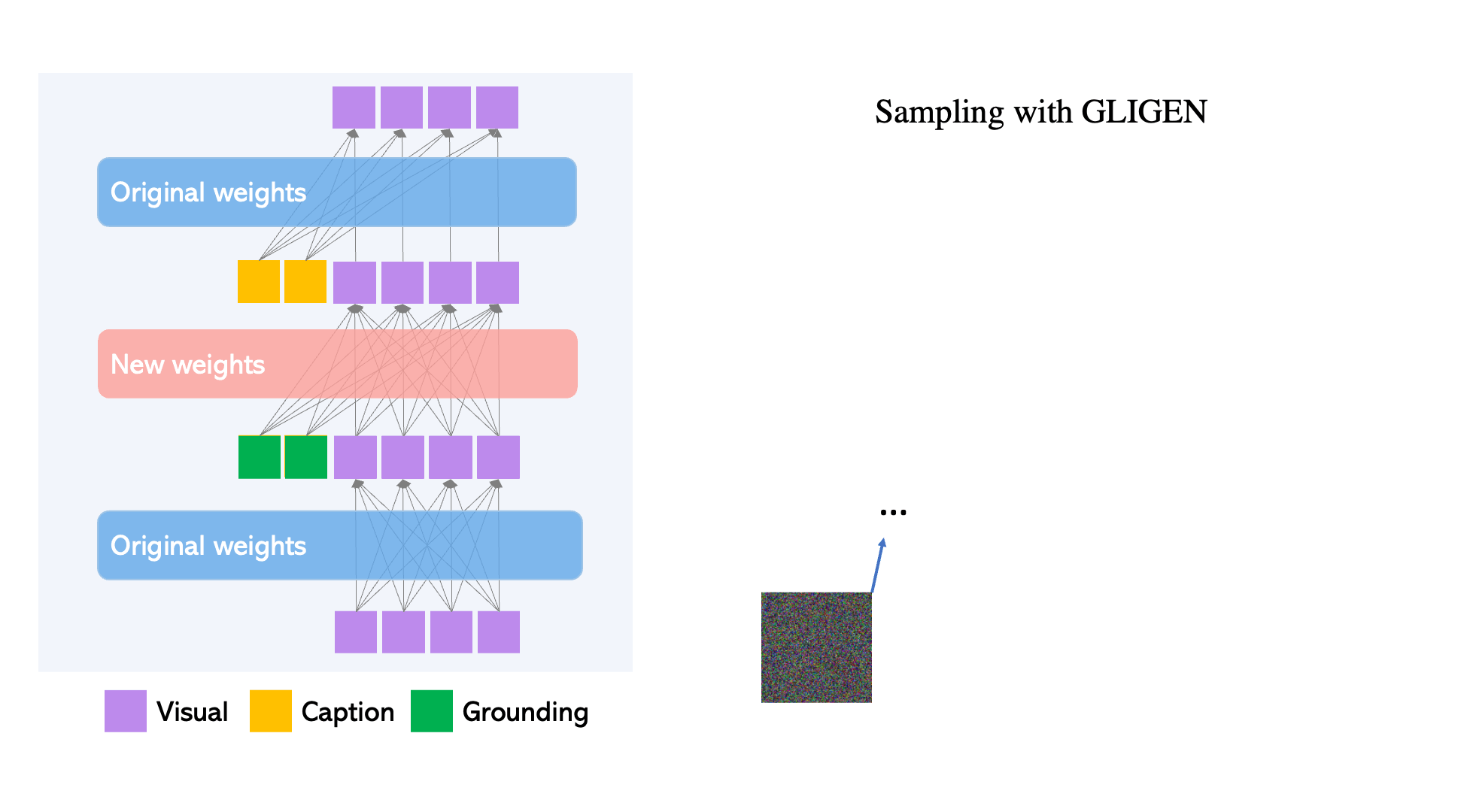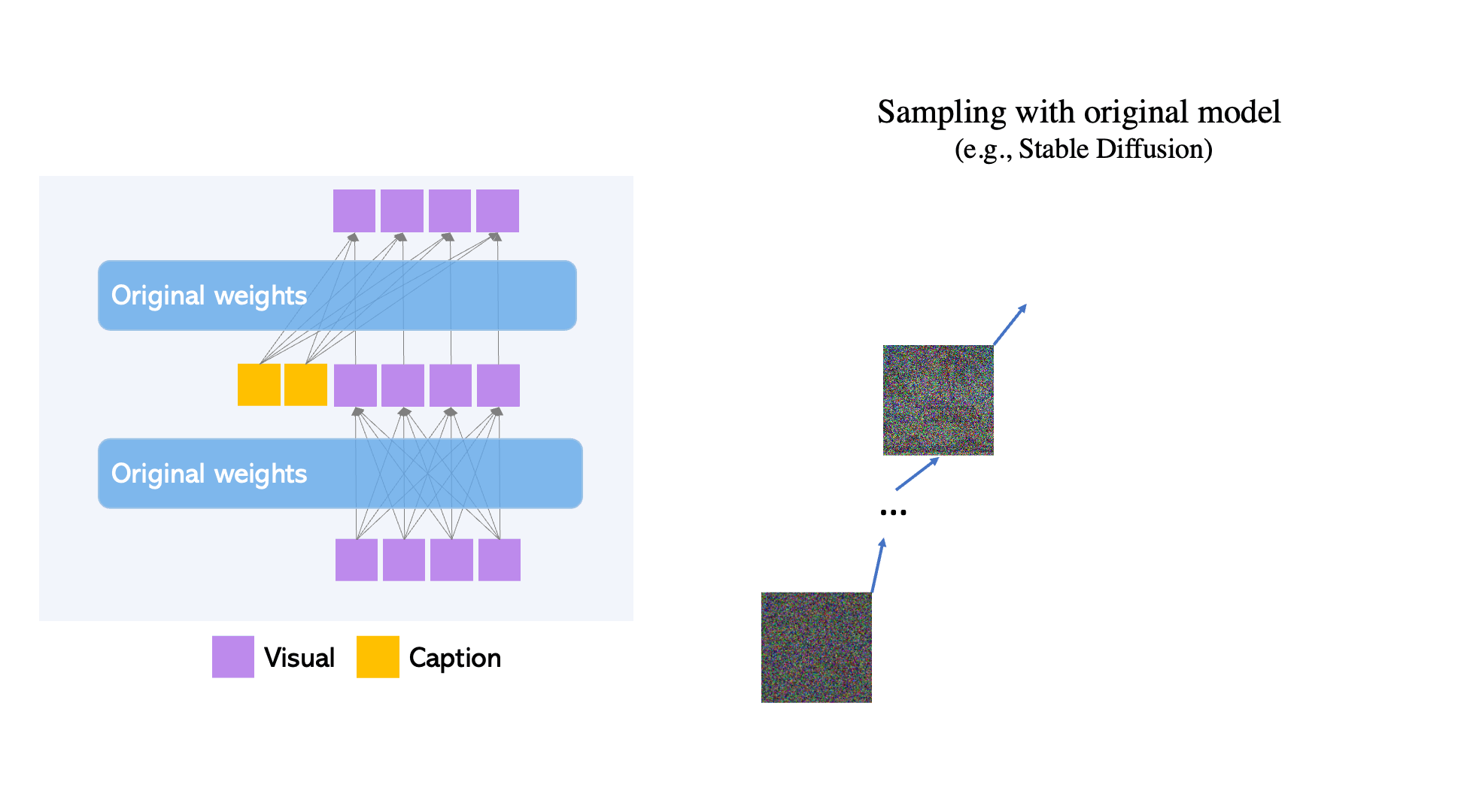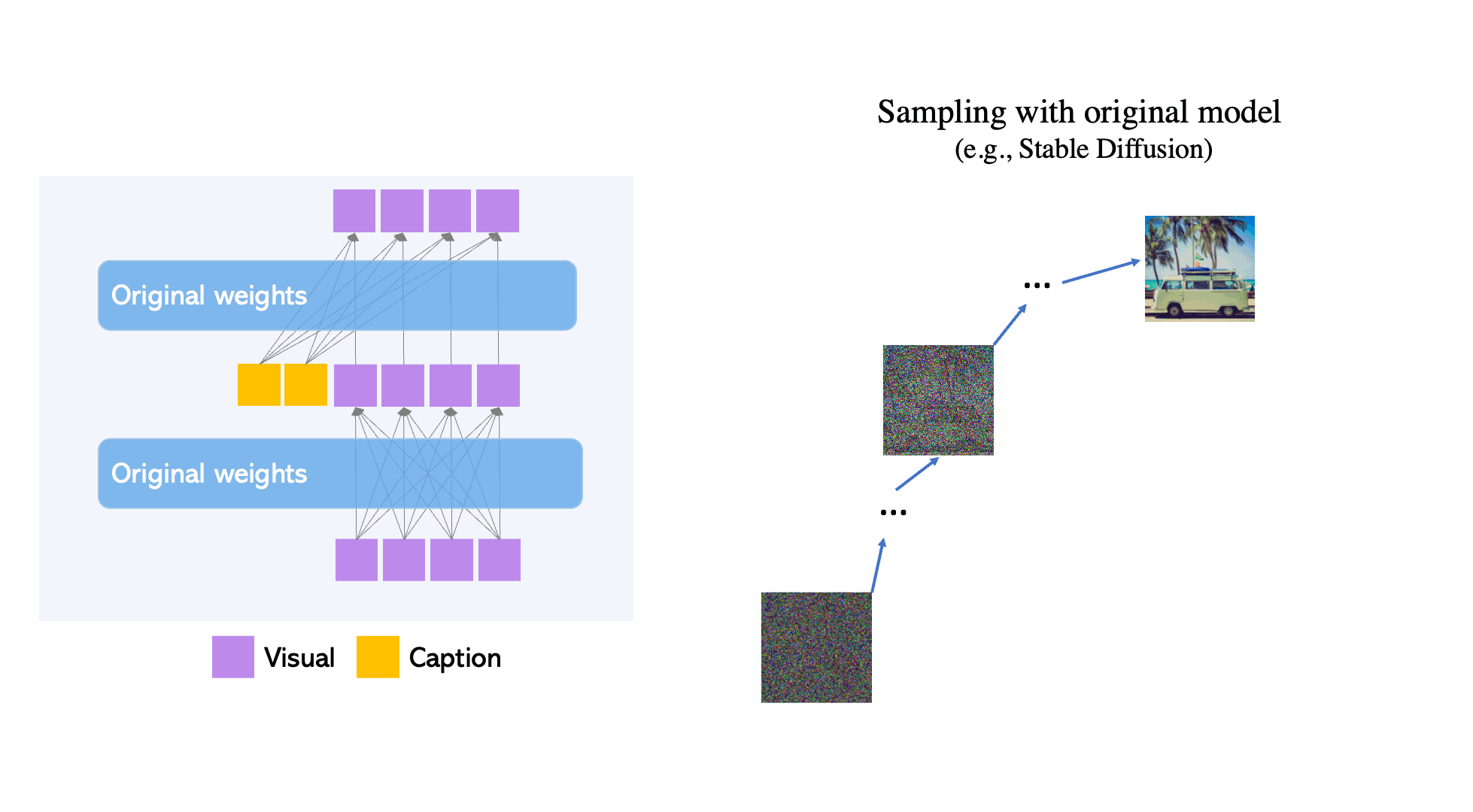
To maintain the pre-trained model’s extensive concept knowledge, developers freeze all of its weights and pump the grounding information into fresh trainable layers via a controlled process. With caption and bounding box condition inputs, GLIGEN model generates open-world grounded text-to-image, and the grounding ability generalizes effectively to novel spatial configurations and concepts.
Check out the demo here.

- GLIGEN is based on existing pre-trained diffusion models, the original weights of which have been frozen to retain massive amounts of pre-trained knowledge.
- At each transformer block, a new trainable Gated Self-Attention layer is created to absorb additional grounding input.
- Each grounding token has two types of information: semantic information about the grounded thing (encoded text or image) and spatial position information (encoded bounding box or key points).
| Related article: Microsoft has released a diffusion model that can build a 3D avatar from a single photo of a person |



Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.




