












































Developers Unveil a New GPT-4-Based Method for Self-Assessing LLMs, Achieving 80% Agreement with Human Evaluations







In Brief
The LLM evaluation method has evolved to improve accuracy and fairness in assessing language models.
The authors used a GPT-4 comparison approach, involving tens of thousands of real human responses, to gather data and address challenges such as estimation bias, verbosity preference, self-assertion bias, and limited reasoning ability.
In a recent series of articles discussing the evaluation of LLMs, it was highlighted that scalability and cost-effectiveness led to the adoption of a GPT-4 comparison approach. This involved using one model to evaluate different answers to the same question, selecting the best response to create a ranking system. As previously mentioned, this method had notable limitations. The creators of the LMSYS.org rating, who introduced this approach a few months ago, have now decided to replace it with a new evaluation method.

Over the course of their work, the team gathered tens of thousands of real human responses comparing preferences for different answers. This extensive dataset allowed them to gain a more accurate understanding of the pros and cons associated with each response. The new evaluation method still relies on GPT-4, employing automation and scalability. It is accessible to everyone at an affordable price point.
To ensure fairness in the evaluation process using GPT-4, the following challenges were addressed:
- Estimation bias resulting from position preference.
- Predisposition to verbosity, favoring longer answers without considering their quality.
- Self-assertion bias, where preferences are inclined towards the model’s own answers or models trained on them.
- Limited reasoning ability when assessing mathematical and logical questions.

You can view all questions, all model responses, and pairwise comparisons between more than 20 models on a dedicated website (https://huggingface.co/spaces/lmsys/mt-bench). As usual, the Reasoning and Coding sections contain the most fascinating examples.
After implementing various solutions to mitigate these issues, the authors discovered that powerful language models like GPT-4 align well with human preferences, achieving over 80% agreement in evaluations. This means that the model’s assessment coincides with human ratings in 80% of cases, a level of agreement comparable to two different human evaluators working on the same task. OpenAI has also reported that even co-authors of an article, who closely collaborate, agree in 82-86% of cases.
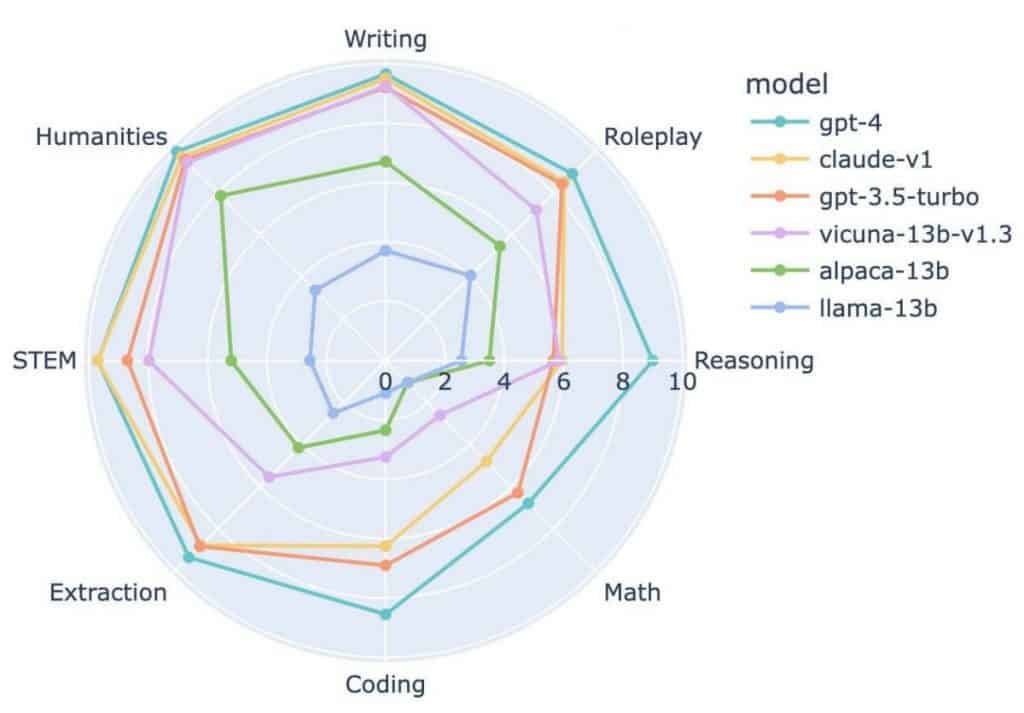
It is important to note that while this is not a “perfect way” of evaluation, it represents a significant improvement over previous methods. The authors are now aiming to expand their dataset to include 1000 questions instead of 80, and they are actively working on refining prompts to reduce biases in GPT-4 estimates. They consider two more objective assessments: one based on voting by real people (known as “arena,” where models compete) using Elo points, and another based on predictions from the MMLU benchmark.
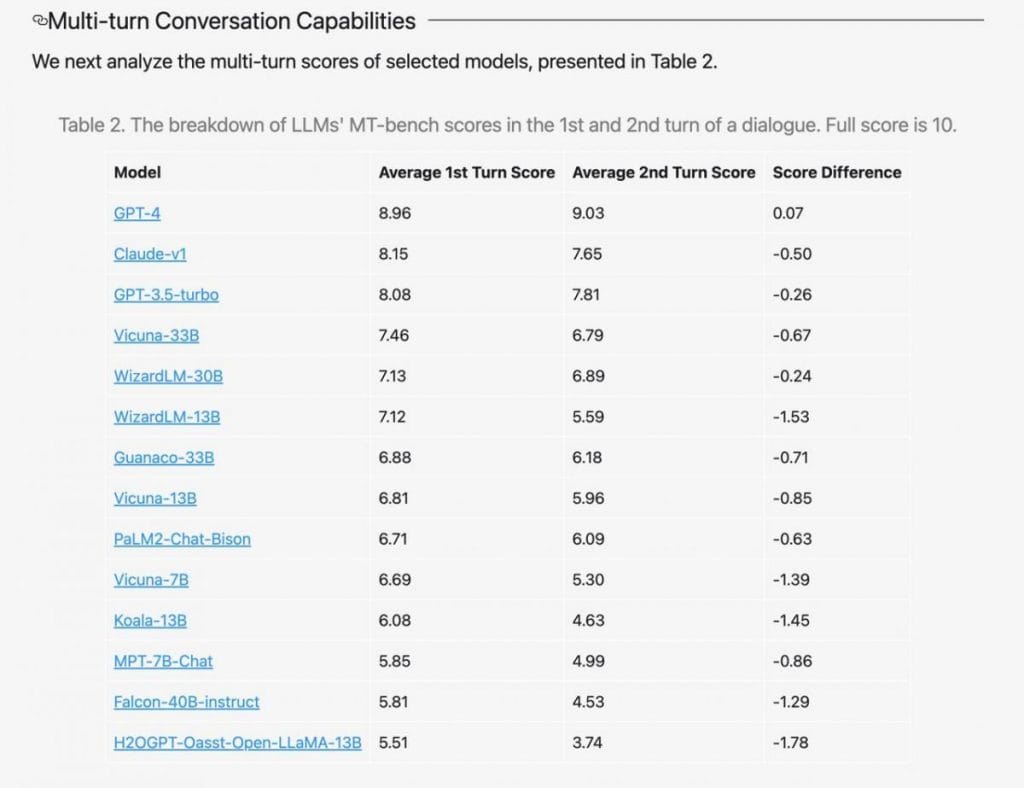
Enhancing Model Comparison with GPT-4
With the recent emergence of various language models like Vicuna, Koala, and Dolly, the practice of comparing models using GPT-4 has gained popularity. A unique prompt is provided where two answers to the same question, one from model A and another from model B, are inserted. Evaluators are then asked to rate the answers on a scale from 1 to 8, with 1 indicating that model A is significantly better, 8 for model B, and 4-5 representing a draw. Scores of 2-3 and 6-7 indicate a “better model.”
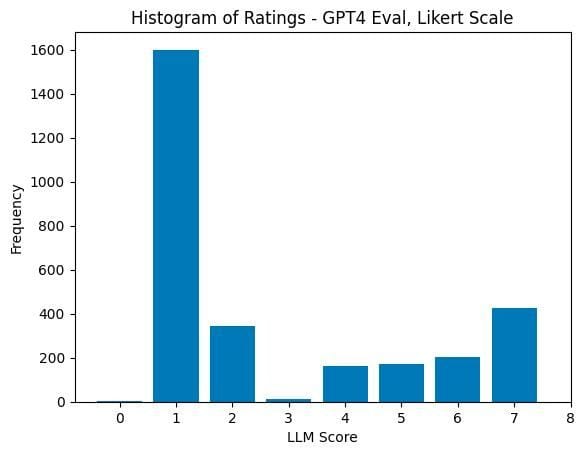
In an insightful study conducted by the team at HuggingFace, they assessed the answers of four models for 329 different questions. Among the interesting findings, the study revealed the following:
- The ranking of the four models based on pairwise comparisons was consistent between human assessment and GPT-4, although different Elo rating gaps were observed. This indicates that the model can distinguish between good and bad answers but struggles with borderline cases that are less aligned with human evaluations.
- Interestingly, the model rated answers from other models, particularly those trained on GPT-4 answers, higher than real human answers.
- There is a high correlation (Pearson=0.96) between the GPT-4 score and the number of unique tokens in the response. This suggests that the model does not evaluate the quality of the answer, emphasizing the need for cautious interpretation.
These findings underscore the importance of careful evaluation when utilizing GPT-4 for model comparison. While the model can differentiate between answers to some extent, its assessments may not always align perfectly with human judgments, especially in nuanced scenarios. It is crucial to exercise caution and consider additional factors when relying solely on GPT-4 scores. By refining prompts and incorporating diverse assessments, researchers aim to enhance the reliability and accuracy of GPT-4 estimates.
The article was written with the support of the telegram channel community.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.




