












































Stability AI Launches Stable Audio for AI-Crafted Audio Generation







In Brief
Stability AI today announced the launch of its inaugural AI product for music and sound generation, Stable Audio.
Users can enter text prompts to generate audio tracks of their desired length.
The underlying model was trained using music and metadata from music library, AudioSparx.

Stability AI, the generative AI company behind Stable Diffusion, today announced the launch of its inaugural AI product for music and sound generation, Stable Audio. The product is geared towards music creators looking to create samples for their music as well as audio tracks. The company said that users can enter text prompts to generate audio tracks of their desired length.
“Post-Rock, Guitars, Drum Kit, Bass, Strings, Euphoric, Up-Lifting, Moody, Flowing, Raw, Epic, Sentimental, 125 BPM” can be entered with a request for a 95-second track,” Stability AI wrote in a blog post.
The company also detailed the results of how prompt based music generation works in a video:
“We hope that Stable Audio will empower music enthusiasts and creative professionals to generate new content with the help of AI, and we look forward to the endless innovations it will inspire,” Emad Mostaque, CEO of Stability AI, said in a statement.
According to Stability AI, the foundational model was trained using music and metadata from AudioSparx, a music library. The company claims that the Stable Audio model is able to render 95 seconds of stereo audio at a 44.1 kHz sample rate in less than one second on an NVIDIA A100 GPU.
Stability AI said the Stable Audio models are latent diffusion models comprising several components, much like Stable Diffusion. These components include a variational autoencoder (VAE), a text encoder, and a U-Net-based conditioned diffusion model.
As per a research report by the company, the VAE transforms stereo audio into a compact, noise-resistant, and reversible lossy latent encoding. This encoding facilitates faster generation and training compared to working directly with raw audio samples.
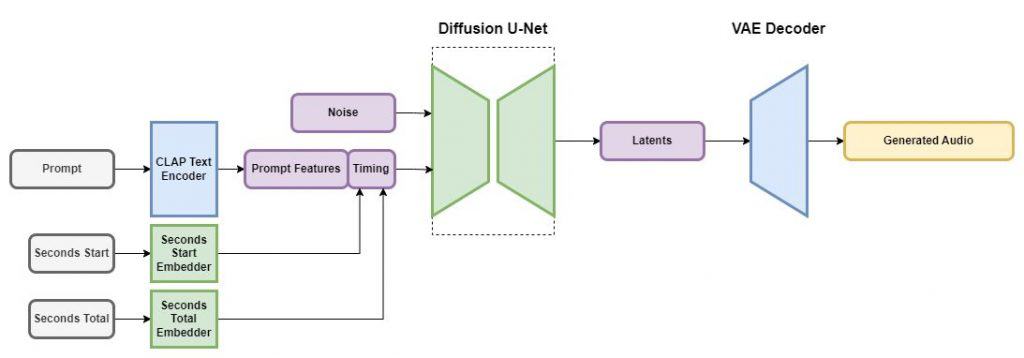
The latent diffusion architecture leverages audio data, taking into account text metadata, audio file duration, and start time. This approach allows control over both the content and duration of the generated audio. To condition the model on text prompts, the audio platform employs the frozen text encoder of a CLAP model that was trained from scratch on its dataset.
A free version of Stable Audio with limited features is available, allowing users to create and download tracks up to 20 seconds in length. Additionally, there is a ‘Pro’ subscription option that offers extended 90-second tracks suitable for commercial projects.
Stable Audio is the latest in a recent series of AI products that Stability AI has released. In August alone, the company released a Japanese language model and Stable Chat, which aims to rival ChatGPT.
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Cindy is a journalist at Metaverse Post, covering topics related to web3, NFT, metaverse and AI, with a focus on interviews with Web3 industry players. She has spoken to over 30 C-level execs and counting, bringing their valuable insights to readers. Originally from Singapore, Cindy is now based in Tbilisi, Georgia. She holds a Bachelor's degree in Communications & Media Studies from the University of South Australia and has a decade of experience in journalism and writing. Get in touch with her via cindy@mpost.io with press pitches, announcements and interview opportunities.
More articles
Cindy is a journalist at Metaverse Post, covering topics related to web3, NFT, metaverse and AI, with a focus on interviews with Web3 industry players. She has spoken to over 30 C-level execs and counting, bringing their valuable insights to readers. Originally from Singapore, Cindy is now based in Tbilisi, Georgia. She holds a Bachelor's degree in Communications & Media Studies from the University of South Australia and has a decade of experience in journalism and writing. Get in touch with her via cindy@mpost.io with press pitches, announcements and interview opportunities.



