












































GPT-4 Solves MIT Exam Questions with 100% Accuracy? Not True, Researchers Say







In Brief
Researchers from MIT examined GPT-4’s performance and found that its assertion of 100% accuracy was not entirely accurate due to self-assessment and repeated questions.
GPT-4 achieved a high success rate, but this is misleading due to the lack of information regarding the timeline and breakdown of the questions.
MIT researchers conducted the experiment with the goal of evaluating GPT-4’s capabilities. They wanted to know if GPT-4 would be able to graduate from their prestigious school and pass the exams. The results were nothing short of astounding, as GPT-4 displayed exceptional competence in a variety of fields, including engineering, law, and even history.

A selection of 30 courses covering a range of topics, from elementary algebra to topology, was made to use in the experiment. There were an astounding 1,679 tasks total, which is equal to 4,550 distinct questions. The model’s capabilities were evaluated using about 10% of these questions, and the remaining 90% served as supplemental information. The remaining questions were either used as a database or to train the models in order to find the questions that were most similar to each test prompt.
The researchers employed multiple methods to aid GPT-4 in answering the questions accurately. These techniques included:
- Chain of Reasoning: Prompting the model to think step by step and express its thoughts directly within the prompt.
- Coding Approach: Instead of providing the final solution, the model was asked to write code that would yield the answer.
- Critic Prompt: After providing an answer, a separate prompt (a total of 3 unique prompts) was added to evaluate the solution, identifying any errors and guiding the model to provide the correct answer. This process could be repeated multiple times.
- Expert Prompting: A key strategy involved adding a specific phrase at the beginning of the prompt, designed to encourage GPT-4 to think like a particular person. For instance, phrases like “You are an MIT Professor of Computer Science and Mathematics teaching Calculus” were pre-generated by the model, offering an educated guess about the three most capable experts to solve the question.
The researchers then combined these methods into chains, often using a combination of two or three prompts. The generated answers were thoroughly examined, including a unique evaluation technique. GPT-4 was presented with a task, the correct answer, and the model’s own generated answer, and asked to determine if it was correct or not.
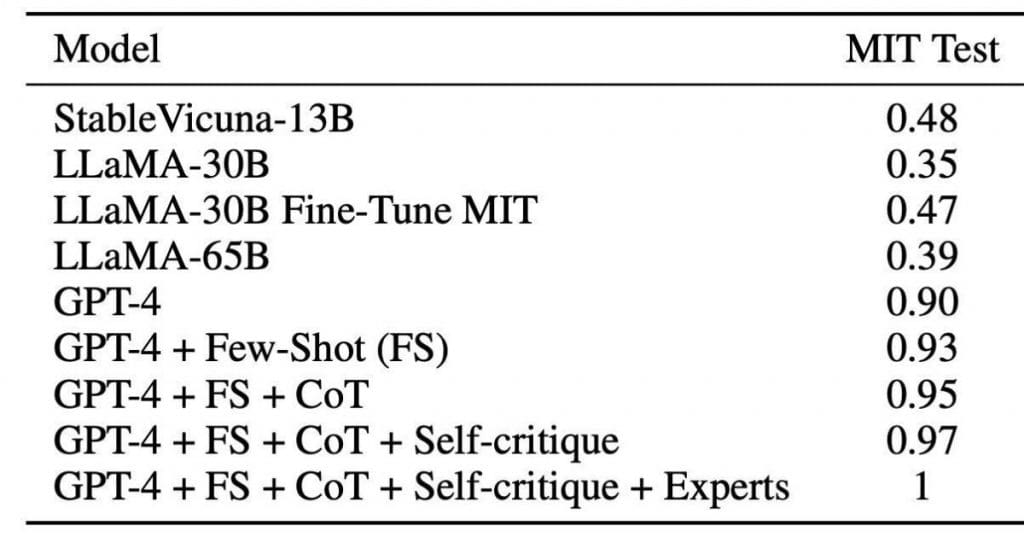
GPT-4 demonstrated a 90% success rate in solving the reserved 10% of questions without the aid of additional techniques. However, when employing the aforementioned tricks, the model achieved a flawless 100% accuracy, flawlessly answering every question. In essence, GPT-4 proved itself capable of flawlessly tackling every task, akin to “earning” an MIT diploma.
The researchers’ work serves as a significant step forward, demonstrating the transformative power of advanced language models like GPT-4.
GPT-4 Hype: Critical Examination of the Model’s Performance
Amidst the fervor surrounding the recent article on GPT-4’s astounding success, a group of researchers from MIT took a closer look at the claims made and raised pertinent questions about the validity of the results. They sought to determine if the statement that GPT-4 achieved a flawless 100% accuracy in answering the test questions held true.
Upon careful examination, it became evident that the assertion of GPT-4’s perfect performance was not entirely accurate. A few crucial points came to light, challenging the credibility of the findings.
Firstly, a notable concern arose regarding the evaluation process itself. The original article mentioned that the model was given a task, along with the correct answer, and then evaluated its own generated response. This self-assessment approach raises doubts about the objectivity of the evaluation, as no external verification was conducted. It is essential to validate the model’s ability to evaluate solutions accurately, which was not addressed in the study.
Moreover, some peculiarities emerged during further investigation. For instance, it was discovered that certain questions were repeated, and when the model was prompted to search for similar questions, it effectively provided the correct answers. This approach significantly boosted the model’s performance but raised questions about the integrity of the evaluation. An example would be asking the model to solve the problem “2+2=?” after already mentioning that “3+4=7” and “2+2=4.” Naturally, the model would possess the correct answer.
Approximately 4% of the questions posed challenges for the language model as they involved diagrams and graphs. Since the model relied solely on text-based input, it was incapable of providing accurate responses to such questions. Unless the answers were explicitly present in the prompt, the model struggled to tackle them effectively.
It was discovered that some of the purported questions were not questions at all. Instead, they appeared to be introductory text or fragments of tasks. This oversight during the evaluation process resulted in the inclusion of irrelevant information in the set of questions.
Another critical aspect that was not addressed in the original work was the lack of information regarding the timeline or breakdown of the questions. It remains unclear whether GPT-4 had encountered these specific tasks on the internet or any other source prior to the experiment. Even without searching for similar questions, the model achieved a 90% success rate, which raises questions about potential external influences.
The aforementioned findings were uncovered in just a few hours of examination, focusing on only a small portion of the published questions. It begs the question of what other inconsistencies might have arisen had the authors shared the complete set of questions and answers, as well as the model’s generation process.
It is evident that the claim of GPT-4 achieving a flawless 100% accuracy is misleading. The original work should be approached with caution and not be taken as a definitive outcome.
Unveiling Positional Bias and Evaluating Model Rankings
The recent trend of comparing models, like Vicuna, Koala, and Dolly, has gained popularity, especially with the emergence of GPT-4, as showcased in the previous example. However, it’s essential to understand the nuances of such comparisons to obtain accurate evaluations.
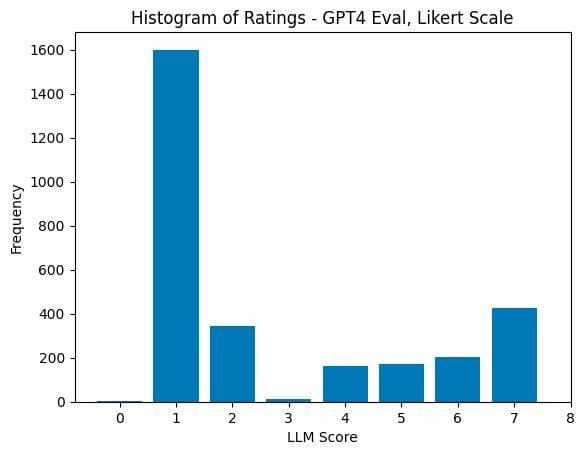
It might seem reasonable to assume that if Models A and B are swapped, the scores would remain the same, with only the labels inverted. However, an intriguing phenomenon called “positional bias” emerges, where the model tends to assign higher scores more frequently to Model A (a rating of 1). Looking at the graph, we can observe that it should be nearly symmetrical around 4-5, as the patterns are shuffled randomly. This symmetrical distribution is usually achieved when human evaluations are performed.
But what if we instruct the model to consider this positional bias and prevent it from excessively assigning units? This approach partially works but results in a shift in the graph in the opposite direction, although to a lesser extent.
A study conducted by the researchers at HuggingFace examined the answers provided by four models to 329 different questions. The findings offer valuable insights, with several intriguing observations worth highlighting:
Firstly, when comparing the rankings of the four models based on pairwise comparisons, the assessments made by GPT-4 and human evaluators aligned. The Elo rating system revealed differing gaps in the model rankings. This suggests that while the model can distinguish between good and bad answers, it faces challenges in accurately assessing borderline cases that are more similar to human evaluations.
GPT-4 tends to rate the answers of other models (trained on GPT-4 answers) higher than those provided by real human evaluators. This discrepancy raises questions about the model’s ability to accurately gauge the quality of answers and emphasizes the need for careful consideration.
A high correlation (Pearson=0.96) was observed between the GPT-4 score and the number of unique tokens in the response. This finding further underscores that the model’s evaluation does not necessarily reflect the quality of the answer. It serves as a reminder to exercise caution when relying solely on model-based evaluations.
The evaluation of models requires a nuanced understanding of potential biases and limitations. The presence of positional bias and the differences in rankings highlight the need for a comprehensive approach to model assessments.
Exploring Model Evaluation Methods
In their research, the authors employed a series of methods in a sequential manner. If GPT-4 was unable to answer a question, it was presented with the three most similar examples from the prompt and asked to solve it. If the model still couldn’t provide an answer, the phrase “think step by step” was added. And if the model failed again, they resorted to writing code. Consequently, any questions that GPT-4 answered correctly (according to its own evaluation) were not asked again.
One might argue that this approach seems absurd, as it effectively entails examining the correct answers. It’s akin to having someone scrutinize your exam solutions, declaring them incorrect until they encounter a correct one, at which point they stop criticizing and you refrain from making further changes. While this method may not be replicable in real-world production scenarios due to the absence of a definitive correct answer for comparison, it does shed light on an interesting perspective.
From a metric standpoint, this approach raises fairness concerns. If the model is given even a prompt of criticism for the correct answer, wherein it is asked to find mistakes and make corrections, there is a risk of transforming a correct decision into an incorrect one. In such a scenario, the answer may change, and the outcome becomes skewed.
Ideally, a comprehensive article would have explored the implications of this approach, including how it affects metrics and the impact on overall quality. Unfortunately, the current article falls short in these aspects.
The research does provoke thought and contemplation regarding different evaluation methods and the notion of validating intermediate steps.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.
More articles
Damir is the team leader, product manager, and editor at Metaverse Post, covering topics such as AI/ML, AGI, LLMs, Metaverse, and Web3-related fields. His articles attract a massive audience of over a million users every month. He appears to be an expert with 10 years of experience in SEO and digital marketing. Damir has been mentioned in Mashable, Wired, Cointelegraph, The New Yorker, Inside.com, Entrepreneur, BeInCrypto, and other publications. He travels between the UAE, Turkey, Russia, and the CIS as a digital nomad. Damir earned a bachelor's degree in physics, which he believes has given him the critical thinking skills needed to be successful in the ever-changing landscape of the internet.




